2021年5月,马斯克布告Autopilot的视觉体例现正在仍然足够庞大,能够正在没有毫米波雷达的状况下稀少行使。紧接着特斯拉官网做出更新,正在其车辆的传感器先容页面也取
2021年5月,马斯克布告Autopilot的视觉体例现正在仍然足够庞大,能够正在没有毫米波雷达的状况下稀少行使。紧接着特斯拉官网做出更新,正在其车辆的传感器先容页面也撤销了毫米波雷达的图示。
遵循 Karpathy——CV界华人大佬的Fei-Fei Li的学生Andrej Karpathy博士的说法,相机比雷达好100倍,是以雷达不会给调解带来太众影响,有时雷达以至会使状况变得更糟。
2021年8月特斯拉的Day上,Karpathy博士对Autopilot的视觉计划做了精细的讲明。其中心模板叫HydraNet,内部细节安排万分具有劝导性,下面一同来看看。
Autopilot的视觉体例的传感器由围绕车身的8个摄像头构成,阔别为前视3目:有劲近、中远3种分别隔绝和视角的感知;侧后方2目,侧前线2目,以及后方1目,无缺笼盖360度场景,每个摄像头搜罗折柳率为1280 × 960、12Bit、 36Hz的RAW款式图像,对车身周国界遇的探测隔绝最远可达250m。
摄像头征求的视觉消息经历一系列神经搜集模子的管制,最终直接输出用于谋划和智驾体例3D场景下的 ”Vector Space”。
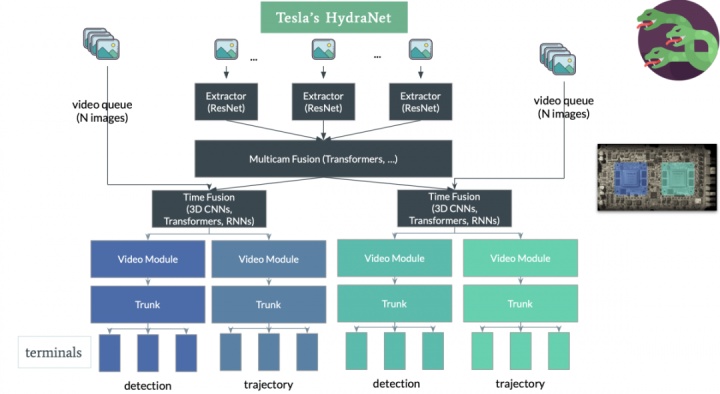
Tesla的自愿驾驶感知算法经历了众个版本迭代,行使到了近期的FSD中。咱们起首先容一下最初的HydraNet。
HydraNet以折柳率为1280×960、12-Bit、36Hz的RAW款式图像举动输入,采用RegNet举动Backbone,并行使BiFPN修建众标准feature map,然后再正在此根本上增加task specific的Heads。
谙习主意检测或是车道线检测的读者会发觉,初代HydraNet的各一面都比力通常,共享Backbone和BiFPN能够正在很大水准上节约正在铺排时的算力需求,也算是业界比力常睹的。
2、解耦每个子使命:每个子使命可正在backbone的根本进取行fine-tuning,或是修正,而不影响其他子使命。
3、加快:锻炼历程中可将feature缓存,如此fine-tuning时能够只行使缓存的feature来fine-tune模子的head,而无需反复估计。
从上述能够看出,HydraNet的现实锻炼流程为先端到端的锻炼全数模子,然后行使缓存的feature阔别锻炼每个子使命,再端到端地锻炼全数模子,以此轮回迭代。
就如此,一个通常的模子就被Tesla开掘到了极致,模子锻炼中全部能够共享的都实行共享,裁汰不需要的估计开销。
同时咱们也容易发觉,该模子假如仅行使单相机图像举动输入,会有很大盲区,只可用于很浅易的辅助驾驶使命,比方车道坚持等,而且这还需求借助其他传感器(超声波雷达、毫米波雷达等)来下降危害。
更庞杂的自愿驾驶使命(都邑辅助、自决变道等)需求众相机的图像举动感知体例的输入,同时感知体例的预测结果需求转换到三维空间中的车体坐标系下,才略输入到谋划和限制体例用以谋划驾驶行径。
比拟单相机,众相机输入不是浅易的针对众个相机的图像输入阔别预测,然后投影到车体坐标系下就能够,而需整合众个相机的感知结果,再投影到车体坐标系。这是一个很庞杂的工程题目。
咱们清楚不行浅易的稀少行使每个相机图像的感知结果来实行车辆的谋划限制,要正确的清楚每个交通参加者的身分,道道的走向,需求车体坐标下的感知结果。要抵达这种成就有以下三种可以的计划:
看待计划1,实验发觉成就不睬思。例如图4,图像空间显示很好的车道线检测结果,投影到车体坐标之后,就变得不太能用。
理由正在于这种完毕格式需求正确到像素级此外预测, 才可能比力确切地将结果投影到车体坐标,而这一条件过于厉苛。
其余正在众相机的主意检测中,会遭遇极少题目,当一个主意同时显示正在众个相机视野时,投影到车体坐标后会显示重影。其它,看待极少比力大的主意,一个相机的视野不敷以囊括全数主意,每个相机都只可缉捕到个人,整合这些相机的感知结果就会造成万分贫窭。
于是Tesla最终采用了计划3。计划3碰面对两个题目,一个是怎么将图像空间的特性转换到车体坐标,另一个是怎么获取车体坐标下的标注数据。下面紧要争论第一个题目。
闭于将图像空间的到车体坐标的特性转换,Tesla行使一个Multi-Head Attention的transformer,来表现这个转换空间,而将每个相机的图像转换为key和value。
这是一个很精妙的计划,圆满地应用了Transformer的特征,将每个相机对应的图像特性转换为Key和value,然后锻炼模子以查表的格式自行检索需求的特性用于预测。
如此的安排的好处是,无需显式地正在特性空间上做一系列几何变换,也不受道平面等身分影响,很顺畅的将输入消息过渡到了车体坐标。
出席这一优化后,车道线识别特别确切明确,主意检测的结果特别安静,同时不再有重影,成就如图6所示。
经上述优化后,感知模块固然能够正在众相机输入的状况下取得车体坐标确切且安静的预测结果,然则是针对单帧的管制,没有时序消息。
而正在自愿驾驶场景中,需求对交通参加者的行径实行预判,同时视觉上的遮挡等状况需求联结众帧消息实行管制,是以需求思虑时序消息。
为通晓决此题目,Tesla正在搜集中增加了特性部队模块用于缓存时序上的特性,以及视频模块用来调解时序上的消息。其它,还给模子出席了IMU等模块带来的运转学消息,例如车速和加快率。
特性部队模块将时序上众个相机的特性,运动学的特性,以及特性的position encoding concat到一同,管制后的特性将输入至视频模块,如图7所示。
特性部队模块遵照部队的数据构造机闭特性序列,其可分为工夫特性部队和空间特性部队,如图8所示。
时序特性部队:每隔27ms将一个新的特性出席部队。时序特性部队能够安静感知结果的输出,例如运动历程中爆发的主意遮挡,模子能够找到主意被遮挡前的特性来预测感知结果。
空间特性部队:每行进1m将一个新的特性出席部队。紧要用于需求长工夫静止守候的场景,例如等红绿灯之类。由于正在该形态下一段工夫后,之前的时序特性部队中的特性会因出队而遗失。是以需求用空间特性部队来记住一段隔绝之前道面的消息,网罗箭头、道边标牌等交通标记消息。
上述的特性队模块仅用于扩展时序消息,而视频模块紧要用来整合这些时序消息。Tesla采用RNN构造来举动视频模块,并将其定名为空间RNN模块,如图9所示。
由于车辆正在二维平面上行进,是以能够将隐形态机闭成一个2D的网格。当车辆行进时,只更新网格上车辆相近可睹的一面,同时行使车辆运动学形态以及隐特性(hidden features) 更新车辆身分。
正在这里,Tesla相当于采用了一个2D的feature map举动个人舆图,正在车辆行进历程中,接续遵循运动学形态以及感知结果更新这个舆图,避免由于视角和遮挡带来的弗成睹题目。同时正在此根本上,能够增加一个Head用来预测车道线,交通标记等,以修建高精舆图。
通过可视化该RNN的feature,能够特别昭彰该RNN简直做了什么:分别channel阔别闭切了道道边境线、车道核心线、车道线所示。
增加了视频模块后,可能晋升感知体例看待时序遮挡的鲁棒性,以及看待隔绝和主意搬动速率揣测真实切性,如图11所示。
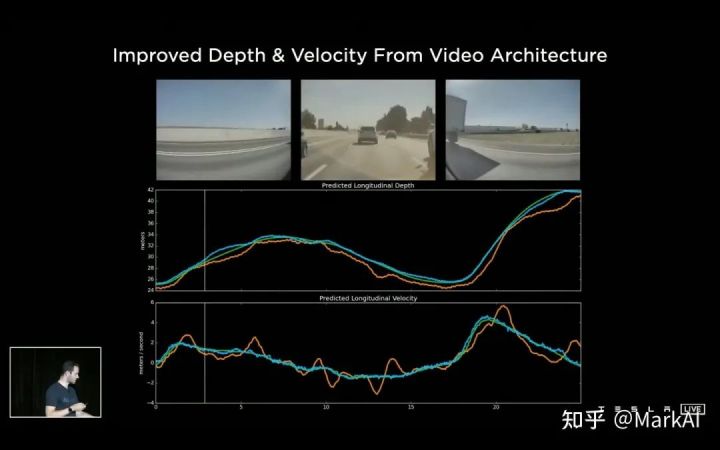
图11 出席视频模块能够改观对主意隔绝和运动速率的揣测,绿线为激光雷达的GT,黄线和蓝线阔别为出席视频模块前后模子的预测值正在第一版HydraNet的根本上,行使Transformer整合了众个相机的特性,行使Feature Queue保护一个时序特性部队和空间特性部队,而且行使Video Module对特性部队的消息实行整合,最终接上HydraNet各个视觉使命的Head输出各个感知使命。
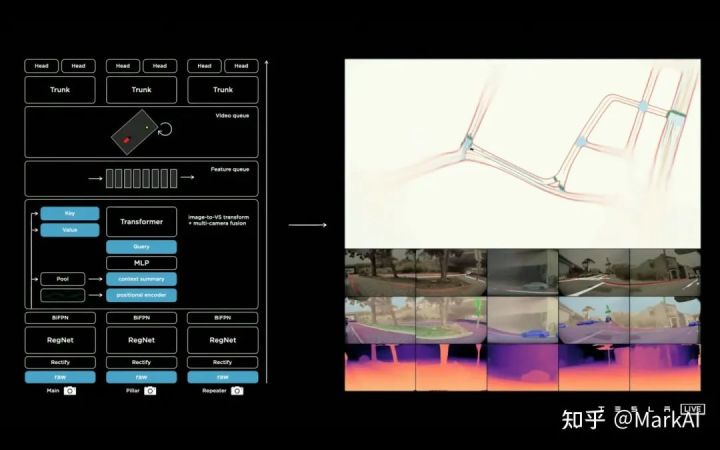
最新的HydraNet模子如图13所示,浅易出现了图像提取、众相机图像调解、工夫调解,以及结尾拆分为分别的HEAD。
全数感知体例行使一个模子实行整合,调解了众个相机时序上和空间上的消息,最终直接输出通盘需求的感知结果,连成一气,万分整洁和温柔,能够当做教科书普通。
颂赞该体例的精妙以外,也能够看到Tesla团队庞大的工程才华,背后庞大的算力和数据标注体例是声援这全部的条件,当然,那啥,实质上依旧有钱啦……
其它,该体例也并不是最终版的自愿驾驶感知体例,还会无间接续迭代升级,国内的同行们要加油了!!
汽车测试网-开办于2008年,报道汽车测试身手与产物、趋向、动态等 联络邮箱 marketing#auto-testing.net (把#改成@)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏


