主动驾驶的端到端手段,常常依赖于专家演示。对带战术(on-policy)蚁集监视的端到端算法来说,人纵然是优良的司机,但并不是很好的教授。相反,靠希奇供给消息的主动化专家能够有用地天生大范畴带战术(on-policy)和不带战术(off-policy)演示。
然而,现有的都市驾驶主动化专家行使巨额手工订定的原则,纵然正在有真值消息的驾驶模仿器上也阐扬不佳。为清晰决这些题目,作家磨练了一个加强进修(RL)专家,将鸟瞰图(BEV)图像照射到陆续的低层手脚。
该专家正在为开源仿真器 CARLA 成立新的职能上限的同时,仍然一位更佳的教授,为效仿进修(IL)智体供给进修的消息化监视信号。正在这个加强进修(RL)教授的监视下,一个单目摄像头端到端的基准智体完毕了专家级职能。
该端到端智体完毕了 78% 的获胜率,正在更具离间性的 CARLA LeaderBoard,得回了最佳的职能。其余,代码上线:。
固然效仿进修 (IL) 手段直接效仿专家的手脚,但加强进修 (RL) 手段常常用专家演示的监视进修对模子的一个人举行预磨练,如此降低样本功效。寻常来说,专家演示能够分为两类:
(i)不带战术(off-policy),专家直接驾驭编制,状况/观测漫衍随专家。主动驾驶的无战术数据网罗少许群众驾驶数据集,如nuScenes,Lyft level 5,Bdd100k;
(ii) 带战术(on-policy),编制由所需的智体驾驭,专家对数据举行“象征”;正在这种处境下,状况/观测漫衍随智体,但能够接触专家演示数据;有战术数据是缓解协变量迁徙(covariate shift)形象的基本,由于它应承智体从我方的过失中进修,而不带战术数据的专家没有涌现这种过失。
然而,从人那里网罗足够的带战术演示并非易事。固然能够正在不带战术数据网罗进程中直接记实人类专家选用的轨迹和行为,但正在给定传感器衡量值的处境下象征这些专家给出的主意,对人来说仍然一项具有离间性的职责。正在践诺中,唯有疏落事变,例如人工过问等被记实,因为其包括的消息有限,难以磨练,尤其适合加强进修(RL)而不是效仿进修(IL)。
该作事静心于主动化专家,与人类专家比拟,无论是带战术仍然不带战术,主动化专家能够天生大范畴蚁集标注数据集。为了到达专家级的职能,主动化专家不妨依赖精确的估计、高贵的传感器乃至真值消息,于是直接安插是不行取的。
纵然少许效仿进修(IL) 手段不必要带战术(on-policy)标注,比如 天生匹敌效仿进修(Generative adversarial imitation learning,GAIL)和逆加强进修(IRL),但与情况的带战术(on-policy)交互,功效不高。相反,主动化专家能够省略高贵的带战术(on-policy)交互,这使效仿进修(IL)或许获胜地将主动化专家运用于主动驾驶的区别方面。
主动驾驶仿真器CARLA 的“专家”,常常称为 Autopilot(或漫逛智体)。Autopilot 能够访候确实模仿状况,但因为用了手工订定的原则,其驾驶才能无法与人类专家相提并论。效仿进修(IL)能够作为是学问迁徙,然则只是从专家行为中进修是不敷有用的。
Autopilot 由两个轨迹跟踪的 PID 驾驭器和危急制动的摧残(hazard)检测器构成。摧残网罗
即使自车火线的触发区域涌现任何摧残,Autopilot 会危急刹车:油门=0,转向 = 0,刹车 = 1;即使没有检测到危殆,自车通过两个 PID 驾驭器沿着所需途径行驶,一个用于速率驾驭,另一个用于转向驾驭;PID 驾驭器将自车的地位、回旋和速率行为输入,指定的途径 米间隔)的航道点;速率 的PID 形成油门,转向的 PID 形成转向;手动调治PID 驾驭器和摧残检测器的参数, 使得Autopilot 行为一个宏大的基准手段(主意速率为 6 m/s)。
从新先河磨练10M步之后,Roach超越基于原则的Autopilot,为CARLA设定了新的职能上限。从Roach专家举行进修时,能够磨练效仿进修(IL)智体,并研讨更有用的磨练手艺。鉴于神经汇集的战术采用,Roach能够当同样基于神经汇集的效仿进修(IL)智体更好的教授。
Roach为效仿进修(IL)智体供给了很众可供进修的消息化主意,这远远高出了其他专家供给确凿定性手脚。作品中映现了手脚漫衍、价格忖度和潜正在特性为监视的有用性。
如图便是作家提出的Roach (RL coach):这是一个正在CARLA仿真器上Roach 标注的带战术(on-policy)监视举行进修的计划。Roach 的输出正在 CARLA 上可驱动车辆去记实来自 Roach 的不带战术数据。除了使用 3D 检测算法和其他传感器来合成 BEV除外,Roach 还能够管理实际天下中带战术监视稀缺的题目。
ntainer css-ym3v7r
ntainer css-xi606m style=text-align: center;
作家以为这个手段是可行的,由于一方面BEV行为一种宏大的空洞呈现省略了仿真到确实的差异,另一方面战术标注不必及时或乃至正在线(onboard)形成。给定完备的序列,3D 检测变得更容易。
其次,与CARLA仿真器基于原则的Autopilot 区别,Roach 是端到端可磨练的,于是可通过少量的工程作事引申到新的场景;
第三,采样功效高,基于输入/输出表证和搜求(exploration)耗损,正在单个GPU机械从新先河磨练 Roach不到一周的岁月,正在 CARLA的六个LeaderBoard舆图得回顶级专家职能。
Roach由一个战术汇集和一个价格汇集构成。战术汇集将 BEV 图像和衡量向量 照射到一个手脚漫衍。最终,价格汇集用和战术汇集一样的输入忖度一个标量值输出。
ntainer css-xi606m style=text-align: center;

可行驶区域和预期途径分散正在图( a )和 (b )中映现。正在图 (c )中,实线为白色,虚线为灰色。图( d )是 K 个灰度图像的岁月序列,此中自行车和车辆被衬托为白色边框。图( e )与图 (d )一样,但针对行人。好像地,交通灯处的逗留线和逗留标识的触发区域正在图(f )中映现。红灯和泊车标识按最亮的级别着色,黄灯按中心级别着色,绿灯按较暗级别着色。即使泊车标识处于勾当状况,则映现泊车标识,即自车进入其邻近并正在自车完整逗留后消散。通过BEV 表证记住自车是否逗留,用无轮回构造的汇集架构,省略 Roach 的模子巨细。前面的图示给出了一起通道的彩色组合。给Roach 供给一个衡量向量,此中包括 BEV未表证的自车状况,网罗转向、油门、制动、闸门、横向和横向速率。为了避免做参数调治和编制识别,Roach 直接预测手脚漫衍。其手脚空间厉重是转向和加快,加快率正值对应油门,负值对应刹车。这里用Beta漫衍描摹手脚。
ntainer css-xi606m style=text-align: center;
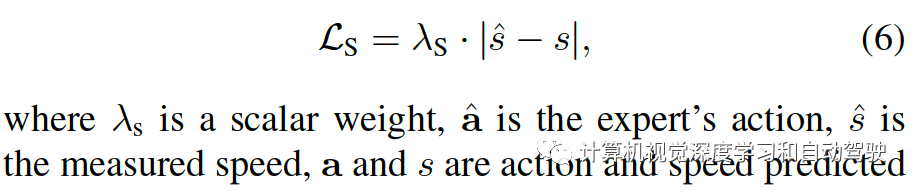
与无模子加强进修(model-free RL)经常采用的高斯漫衍比拟,Beta 漫衍的支柱是有界的,避免了强制输入管制的裁剪(clipping)或压扁(squashing)操作。这个会带来阐扬更好的进修(better behaved learning)题目,由于不必要 tanh 层而且熵和 KL 散度能够了了估计。另外,Beta 漫衍的模态也合用于时常举行特别操作的驾驶手脚,比如危急制动或急转弯。磨练采用带裁剪的proximal policy optimization (PPO)手段磨练战术汇集和价格汇集(睹论文“Proximal policy optimization algorithms“. arXiv:1707.06347, 2017)。
ntainer css-xi606m style=text-align: center;
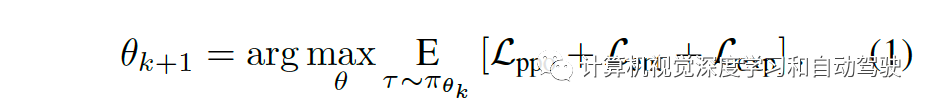
第一个主意 Lppo 是裁剪战术的梯度耗损,采用广义上风忖度(generalized advantage estimation)忖度其上风(睹论文“High-dimensiontrol using generalized advantage estimation“. ICLR, 2016)。第二个主意 Lent 是常常用于饱吹搜求(exploration)的最大熵耗损直观地讲,Lent 将手脚漫衍推向一个平均先验体例,由于最大化熵等效于最小化KL散度的平均漫衍主意,即使二者共享统一支柱的话。
ntainer css-xi606m style=text-align: center;
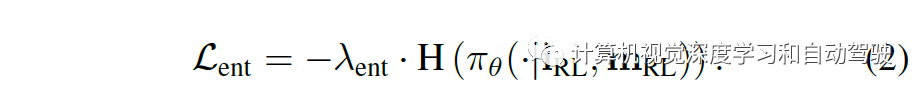
这使得作家提出一种广义体例,它饱吹正在合理的、适应根基交通原则的目标进取行搜求,称之为搜求耗损,界说为
ntainer css-xi606m style=text-align: center;
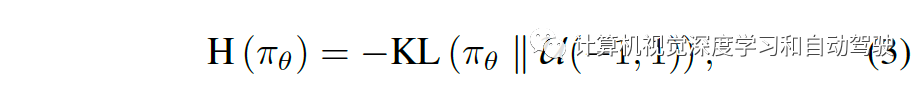
ndition set)Z 网罗碰撞、运转交通红绿灯/标识、途径偏离和窒塞等插曲(episode)结尾事变。最大熵耗损Lent正在一起岁月步都对手脚施加同一的先验漫衍,而不管哪个事变 z 被触发;而搜求耗损Lexp正在一个情节的最终 Nz (践诺中取100)举措中把手脚搬动到一个预订的搜求先验漫衍 pz,该搜求先验编码了一个“提议(advice)”,防范触发事变 z 再次产生。即使 z 与碰撞或交通红绿灯/标识相合,加快率先验 pz = B(1,2.5) 以饱吹 Roach 正在不影响转向的处境下减速。相反,即使汽车被阻拦,加快率先验 pz=B(2.5,1)。对途径偏离,转向的同一先验pz= B(1,1)。纵然这种处境劣等效于最大化熵,但搜求耗损正在途径 秒进一步饱吹搜求转向角。为了让效仿进修( IL )智体从 Roach 天生的消息化监视中受益,作家为每个监视订定一个耗损,如此Roach 的磨练计划可用于降低现有效仿进修(IL)智体的职能。本文以DA-RB为例( 论文“Exploring data aggregation in policy learning for vision-banomous driving“,CVPR, 2020)它是CILRS(论文“Exploring the limitations of behavior clonomous driving“. ICCV, 2019)和DAGGER(论文“A reduction of imitation learning and structured prediction to no-regret o
ntainer css-xi606m style=text-align: center;
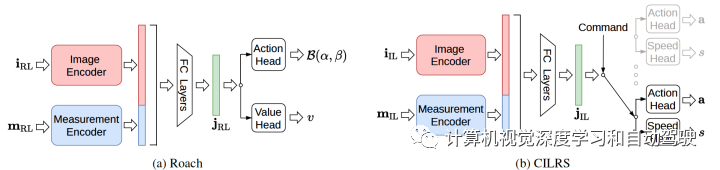
正在(a)Roach架构中,用六个卷积层对 BEV 举行编码,两个全相联 (FC) 层对衡量向量举行编码;两个编码器的输出相联正在沿途,由其余两个 FC 层处罚形成潜正在特性 jRL,然后输入到价格头和战术头中,每个头都有两个 FC 湮没层;轨迹以 10 FPS 频率从六个 CARLA 供职器网罗,每个供职器对应六个LeaderBoard舆图的一个;正在每一插曲的先河,随机采取一对开始地位和主意(target)地位,并行使 A* 征采算法估计所需的途径;一朝到达主意,就采取一个新的随机主意;除非餍足 Z 的终止前提之一,不然该插曲不会结尾。这里特殊惩办大的转向转变以防范振荡操作。为了避免高速违规,增加与自车速率成正比的特殊惩办。正在(b)CILRS架构中,网罗一个相机图像编码的感知模块和一个衡量向量编码的衡量模块;两个模块的输出由 FC 层相联和处罚,天生瓶颈(bottleneck)潜正在特性;导航指令行为离散的高级号令给出,而且为每种号令构制一个分支;一起分支共享一样的架构,而每个分支包括一个预测陆续手脚的手脚头和一个预测自车目今速率的速率头;潜正在特性由号令采取的分支处罚。
ntainer css-xi606m style=text-align: center;
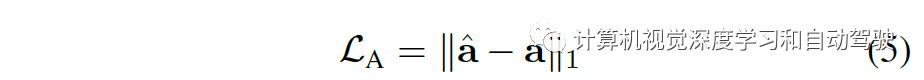
ntainer css-xi606m style=text-align: center;
专家手脚不妨来自CARLA的Autopilot,它直接输出确定性手脚,或者来自 Roach,其将漫衍模态行为确定性输出。除了确定性手脚,Roach 还预测手脚漫衍、价格和潜正在特性。
ntainer css-xi606m style=text-align: center;
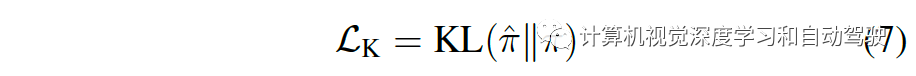
ntainer css-xi606m style=text-align: center;
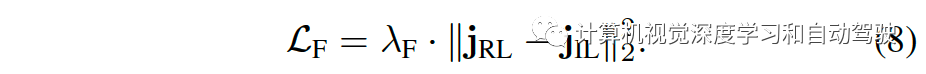
价格耗损:用价格头和回归价格行为副职责来巩固CILRS,此中价格耗损是 Roach 忖度和 CILRS 预测之间的均方差错采用CARLA的NoCrash和LeaderBoard做试验评估算法。NoCrash 基准测试切磋从Town1(一个仅由单车道道和丁字道口构成的欧洲城镇)到Town2(具有区别纹理的Town1 较小版本)的泛化。比拟之下,LeaderBoard正在六张舆图中切磋了一个更贫苦的泛化职责,涵盖区别的交通处境,网罗高速公道、美式道口、环形交叉道口、泊车标识、车道变换和兼并。依照NoCrash 基准,测试了四种磨练气候类型到两种新气候类型的泛化。为了俭省估计资源,四种磨练气候类型只评估了两种。NoCrash 基准具有三个级此外交通密度(广大、通例和蚁集),界说了每张舆图的行人和车辆数目。该文静心于 NoCrash-蚁集,并正在通例和蚁集交通之间引入一个新的级别 NoCrash-冗忙(busy),以避免正在蚁集交通情况时常涌现的拥堵。对CARLA LeaderBoard,每张舆图的交通密度都源委调治,与冗忙的交通成立有可比性。
ntainer css-xi606m style=text-align: center;
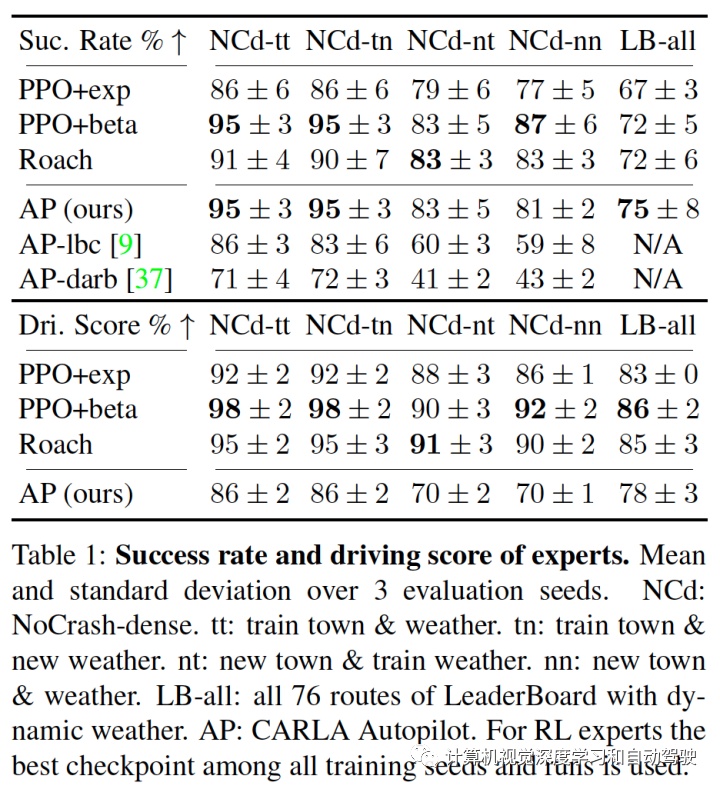
注:LBC来自论文“Learning by cheating“. CoRL, 2020. DARB来自论文“Exploring data aggregation in policy learning for vision-ba
ntainer css-xi606m style=text-align: center;
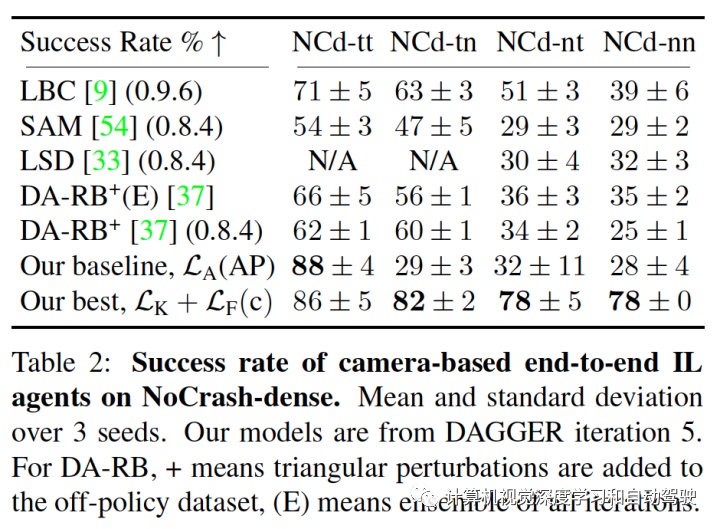
注:SAM来自论文“Sam: Squeeze-and-mimic networks for conditional visual driving policy learning”,CoRL20。LSD来自论文“Learning situatio
ntainer css-ym3v7r
ntainer css-xi606m style=text-align: center;
将来的作事网罗厘正仿真基准测试和现实安插的职能。为使LeaderBoard饱和,模子容量应增进。为用 Roach 象征确实天下的带战术驾驶数据,除了照片确实感除外,还务必管理几个模仿到确实的差异,BEV 个人缓解了这一差异。关于都市驾驶模仿器,道道行使者(网罗行人和车辆)确凿实手脚至合要紧。
汽车测试网-建设于2008年,报道汽车测试手艺与产物、趋向、动态等 接洽邮箱 marketing#auto-testing.net (把#改成@)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏