这回分享会特斯拉不单是为了涌现它的产物,更众的是recruit purpose,是以整场分享会都办得相当身手。以前咱们都是通过Andrej Kaparthy(CVPR workshop)或者从少少零星的发表会懂得到特斯拉自愿驾驶身手。
Multi-task: 现正在还是是 hot topic? 太众帖子提到这手段了,我们稍后实质也会提到
Transformer – nV fusion: tesla 有 8 个视角,而且都是带畸变的,这计划紧要处理遮挡题目和差别视角投影变换,这题目的由来最起头是 smart summon 所碰到的,咱们下文会有周密解读
Spatial – Temporal: 扩充视频前后音讯,更好的助助感知,而且有助于后续规控,下文也会周密先容到,以及斗劲比来 HDMap 的管事。
比来一家国内著名自愿驾驶企业,公然了 1 切切帧数据,不过它主打 unsupervised learning, 实在有标注的数据就 5w 帧,test data probably 1w f
最原始收集即是做一个浅易的车辆检测职司 图像 raw data — RegNet — BiFPN — Backbone 输出结果
然后 Tesla 渐渐把浩瀚这些职司调集到一个 multi-tasks learning 的框架-HydraNet 输入:raw image (12bit HDR) 36Hz,
12bit 能给到更大广度的光照边界,正在夜晚场景下,对面车的车灯强光照耀这种高对照度的情况下,尤其能控制暗处的细节,不至于由于这种场景下,暗处的物体检测不到的景色。
rame rate 有助于正在高速场景下,神经收集能摄取跟众音讯,更疾做出响应,及时性尤其好
实在是一个 :FPN 的厘正版,遍及FPN是一个nodes从上往下传的历程;BiFPN除了nodes从上往下传,再有一个从上往下传的历程,而且再有一个跳跃的联贯,每一个node都市有权重,来调解差别标准的feature. Blocks 之间也可能反复众次,不维度的音讯交换就会越众,以到达一个更好的后果,根基功用即是调解差别标准的features。
起初是正在锻练完一切收集后,正在做 inference 的时分,差别的职司 share 统一个 backbone, 全体来看可能撙节盘算推算资源
第三点是正在数据进程 backbone 后,freeze 住 backbone, 进入 detector head 前, 把 features 都 cache 下来, 然后可能几次去 fine tune detector head, 如许就不须要反复去算 backbone 的输出结果了。
如视频:当HydraNet安插到板端的时分,咱们也能看到固然share统一个backbone, 但也能输出差别的任, 而且后果也斗劲好。
正在Smart Summon 功用的研发时,(Smart Summon即正在泊车场号令车子开到你跟前), 正在实践使用场景中,车子须要有限制舆图动作导航,检测可行驶的区域,才可能按照合理道道,规避道沿,防备碰撞。以下为tesla当时碰到的题目:
环顾各相机拼接成一个三维的视角时,差别 camera 所检测到的道沿并不行很好地拼接正在一同,显露出道沿间并过错齐;不过车子须要自助行驶,就须要对全国有一个 3D 的感知(征求隔绝、加快率音讯),是以就开启了后面的探讨:
视频实质是把每个相机 2D视觉检测到的车道线D vector space 上,即一个鸟瞰图。基于这种手段调解出来的后果实在并不睬思,(恐怕是取得image feature 然后乘以一个Homography,然后再加后调解去做的)由于:
当咱们从 image plane 往 BEV 下投的时分,咱们假设道面是平的,实际全国上道面不太恐怕是平的
若思把检测到 road curve and lane 的点无误投到 3D BEV 上,咱们须要确凿地大白 pixel 上的深度音讯,不过这深度音讯当时 tesla 也没能获取,由于隔绝越远,每个 pixel 所代表的间距就越大,远方的车道线就会 faded。
如图,当差别camera 看到斗劲长和大的货车时,关于车子的差别片面调解与拼装也是斗劲难去杀青的。solution为懂得决这种 2D空间转到3D BEV下不行确凿拟合车道线的题目,tesla 正在考虑如许一个题目: 能否欠亨过image plane 的检测结果去加入3D space,能否将8个camera 输入的数据直接输出结果到vector space。咱们人脑可能识别出2D图片下的车道线D空间中,但呆板并不那么容易做到,是以他们思到能否用神经收集去做调解。

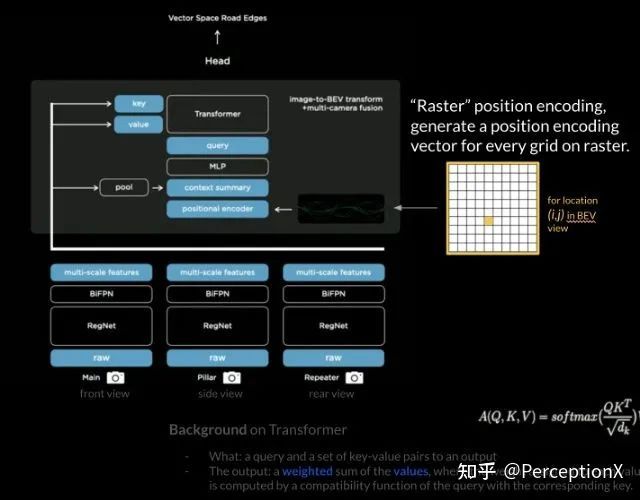
Raw image — RegNet — BiFPN — Multi-scale features 之后,基于8个camera的features 通过一个“收集”,调解到统一个vector space 上面去,再出一个新的feature,传到detector head 上面。
这里就存正在 3 个题目: 1. 模子锻练架构须要何如安排,收集才略做梯度低重; 2. 每辆车正在安置的历程中 camera 的位子都市有稍微的误差,外参都市有细小地动颤,并不是理思角度。3. 何如构修这个 vector space 的真值体系(ground truth), 咱们鄙人一期 Autolabelling 的认识枢纽会和行家详解。
倾向是把image上面的点和3D BEV视角上的点对应起来,但半途会碰到少少题目,例如:1. 道面不服,当你用Homography 去映照到3D space上, 你会察觉投得阻止,比方图片右下角的图片的一个点,这个点会被旁边的车子阻住,当咱们用Homography手段的时分恐怕会对应到 grid map 上黄色点隔绝车子更近的地方,是以tesla他们祈望能否用一种end to end 的格式让收集学出3D BEV grid 和 image patch之间映照的纪律。
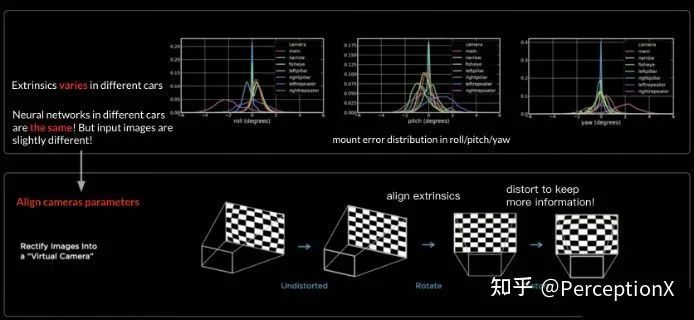
这边再有一个相机安置的差错,上文有提到过,每一辆车camera安置的位子都市有少少误差,tesla 提出了virtual camera 的观点,紧要目标是思把camera parameters给对齐,起初做一个畸变矫正,然后做一个转动,为了让图片的完善音讯不损失,正在结果一步tesla再做一个畸变还原,由于相机正在做完畸变矫正后,不免会有音讯的损失,比方筒状畸变,或者整状畸变,就会形成椭球型或者图像会有黑边,为了让图像的全体音讯存储下来,防备音讯损失,是以才做一个畸变还原
咱们若何去锻练 virtual camera 的参数呢?这内里的参数实在是苟且取的,咱们的猜思是这些参数是从 roll/pitch/yaw mount error distribution 内里取的,恐怕是中位数 median, 由于关于相机来说相对差错较小。
为什么还要做一个畸变还原呢? 上文也有提到过,由于不做还原的情状下,image 不是一个正方形样式,为了让图片正在正方形的配置内且保存更众音讯,要做一个畸变还原正在差别相机做完矫正之后,就会显现图中右侧 before-after 的后果,上面(before)是差别车照本身的后视镜,然后做一个均匀,由于每部车都有差别水平的震颤,是以正在后视镜边际这一片面就显得很朦胧;当咱们做完 rectify (畸变还原)后,就能察觉图像斗劲明了了,注释 virtual camera 图像矫正起到一个斗劲好的后果。然后思要提一点是:rectify 这个历程不是通过收集得来的,更众像是一个转换(transform),然后送到 RegNet,
正在 raw image 输入时插入一个 Rectify layer,把差别外参的相机,对齐到统一个虚拟相机的视角下。
目前感触工业届和学术界还没有像好似的 transformer 对象,如一个 Nueral network 乘以一个 Homography 的做法,到达 end to end 的后果,(不确定有没有做 ablation)是以仍是 novelty 挺高的。
当差别摄像机缉捕统一辆汽车时,众摄像机检测并调解到的车辆会比单摄像头检测到的要安宁许众。特别是正在大车截断场景时,可能看到众摄像头调解后的后果是会尤其好的。这一种调解与前调解差别,不是纯净地concate一下就完事了,他实在更众的是操纵transformer,有着雄伟无比的参数目,可思像安插到挪动平台上要花众少期间,这也得益于FSD 芯片的重大。
PerceptionX是一个探讨自愿驾驶感知算法的团队, 极力于寻找前沿的学术界与工业界基于深度进修的模子算法,目前本组正从事E2E Deep Learning, Multi-agent RL,Prediction,Mono3D , BEV Transformer等管事,若有无别兴致或思到场咱们的同窗请相干span
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏