编者按:近年来,基于车辆运动学与动力学模子的模子预测支配(MPC)表面正在主动驾驶车辆支配方面取得了平常的操纵,MPC基于预先设定的体例模子,通过滚动优化,解
编者按:近年来,基于车辆运动学与动力学模子的模子预测支配(MPC)表面正在主动驾驶车辆支配方面取得了平常的操纵,MPC基于预先设定的体例模子,通过滚动优化,处分设定的优化题目并求解出支配输入。MPC的首要好处正在于可以体例地管束众个优化对象,而且能够管束输入和输出的束缚。本文中提出了一种逆最优支配(IOC)算法用于从人类演示数据中进修本钱函数,将进修取得的本钱函数操纵于途径跟踪MPC中。结果显示,该支配器不只能够从命参考轨迹,还能够使侧向速率、侧向加快率等特色更贴近人类驾驶。
摘要:主动驾驶汽车的途径跟踪支配器正在革新车辆的动态动作方面起着要紧效力。模子预测支配 (MPC) 是最宏大的支配器之一,能够管束众个优化对象,并顺应践诺器和车辆形态的物理局部,以确保平和和其他所需动作。行为一种高潜力的处分计划,能够将人工演示的进修本钱函数集成到 MPC 中。通过从人工演示中进修本钱函数,能够避免巨额参数调治,更要紧的是,能够调治支配器以供给对人类更自然的所需支配行为。正在本探究中,提出了一种更始的逆最优支配 (IOC) 算法,以行使从人工演示中搜集的数据为支配职业进修适应的本钱函数。对象是安排一种支配器,该支配器天生的运动与人类发作的运动的特定特色相成家。这些特色征求侧向加快率、侧向速率和偏离车道核心。从结果中能够看出,安排的支配器可以进修人类驾驶的所需特色并正在天生恰当的支配行为的同时杀青它们。
模子预测支配(MPC)被以为是安排主动驾驶汽车途径跟踪支配器的适应框架。该技能正在每个光阴步处分一个优化题目,而且能够同时管束众个对象。别的,它能够顺应践诺器和车辆形态的物理局部,以确保平和和其他所需的动作。为了为主动驾驶汽车拟定有用的模子预测支配,应当界说恰当的本钱函数。本钱函数的安排往往取决于安排者的体味和醒目水平。当旅客的感想被切磋到车辆职能中时,安排本钱函数会加倍繁杂。
从客观的角度来看,能够通过革新主动驾驶汽车的操控动作来升高人类的安适度和平和性[1]、[2]。这种切磋是对古代车辆乘坐安适性的添加,其首要取决于车辆的振动特色[3]-[5]。从主观角度看,安适度取决于人的感想,难以表述为一构成本函数。行为一种高潜力的处分计划,从人工演示中进修本钱函数从来是探究职员的一个有吸引力的遴选。
为了进修本钱函数或本钱函数的少许参数,很众探究职员提出了逆最优支配(IOC)。正在这种本领中,对付未知的本钱函数,专家演示寻常用作最优支配题目的处分计划[6]。切磋 IOC 处境下的 MPC 题目,对付本钱函数的未知参数,能够将演示输入视为最优输入序列。给定演示数据和参数本钱函数,初阶概述了参数支配的最优前提。别的,IOC 题目能够界说为一种查找算法,用于寻找知足最佳前提的适应参数值[7]。
从演示中预计本钱函数的另一种本领是行使逆加强进修 (IRL)。正在某些情形下,IOC 和 IRL 被彼此界说为雷同的本领。正在 IRL 的布景下,行使诸如马尔可夫计划历程 (MDP) 之类的概率本领从已阐明的最佳动作中提取嘉奖函数[8]、[9]。正在 MDP 本领中,卓殊是对付加强进修 (RL) 的情形,假设本钱函数是已知的。然而,如前所述,为 RL 安排适应的本钱函数同样坚苦。IRL 已被用于因袭进修(有时称为学徒进修),其对象是找到一种支配战略,该战略正在未知嘉奖函数的情形下能体现得和演示者相似好[9]。
很众区别类型的体例提出了IRL和IOC,比方类人机械人[10]、直升机支配[11]和特定驾驶风致的复制[12]。正在[10]中,IRL被提出来寻找嘉奖函数,以行使来自人工演示的数据来安排仿人机械人更自然和动态的运转动作。从模仿结果来看,进修到的嘉奖函数显示出可用于区别处境的杰出泛化特色。纵然优化题目是离线处分的,进修到的嘉奖函数也能够很容易地集成到正在线 MPC 算法中。似乎地,正在[13]中,IOC 被杀青为类人运动支配。不过,正在这种情形下,没有切磋每个闭节的运动;相反,类人机械人的处所和宗旨用于行使双层优化题目来描绘运动。高层支配迭代价格函数的权重,并试图最小化衡量数据与从低层支配搜集的最优支配的解之间的隔绝。
正在主动驾驶的布景下,IRL 已被提出用于预测人类图谋。比方,它用于对人类动作举办筑模,猜想人类驾驶员的门途]中,IRL用于预测驾驶员正在道途上的图谋。人类驾驶员的运动被表述为一个优化题目,并行使IRL找到嘉奖函数。正在[12]中,IRL也被用于正在天生主动驾驶汽车伴随的轨迹时复制局部驾驶风致。正在这项事情中,最大熵IRL[14]用于处分主动驾驶的途径计划题目。别的,本钱函数以似乎于[9]的式样近似为特色的线性组合。IRL的最终对象是为本钱函数的每个特色找到适应的权重,最终用于为车辆天生优化轨迹。
虽然 IOC 和 IRL 已针对上述区别操纵杀青,但据咱们所知,这些技能尚未用于主动驾驶汽车的途径跟踪支配器。切磋到能够通过升高车辆的摆布职能来升高旅客的安适度,基于人工演示数据的基于进修的 MPC 有恐怕顺应这种门径,从而升高旅客的安适度。正在本文中,咱们倡导将 IOC 用于基于进修的 MPC,用于主动驾驶汽车的途径跟踪职业。为了杀青此功效,安排了一种别致的基于特色的 MPC 参数本钱函数。别的,提出了一种更始的 IOC 算法,以行使从人工演示中搜集的数据来进修 MPC 的适应本钱函数参数。数据是行使集成的3D模仿处境“虚幻引擎”和 Matlab-Simulink 平台搜集的。对象是安排一个支配器,发作与人类发作的运动的特定特色相成家的运动。这些特色征求横向加快率、横向速率、与车道核心的隔绝和偏航率。本钱函数的参数是从人工演示数据中进修的。然后行使这些参数来杀青主动驾驶汽车的 MPC 支配器。
本文的其余个别机闭如下。正在第Ⅱ节中,先容了人工演示进修本钱函数背后的表面框架。精确注解了MPC的拟定、本钱函数的界说和IOC的本领论。第Ⅲ节概述了从人工演示中搜集数据的尝试,以及从搜集的数据中进修本钱函数所选用的步调,以及正在途径跟踪支配器中操纵进修到的参数。正在第Ⅳ节和第Ⅴ节中,映现并进一步接洽完结果,并给出了探究的结论。
本事情的首要对象是行使从人工演示中搜集的数据为途径跟踪职业找到适应的本钱函数。道途途径剖面临主动驾驶汽车的操控动作有显着影响[16];正在本事情中,对付给定的参考途径,人工演示的轨迹被以为是最佳处分计划。别的,假设存正在与人类驾驶员天生的轨迹联系联的本钱函数。对象是找到本钱函数的恰当参数,该参数缉捕局部人类驾驶职业的选定特色。正在本节中,最先接洽 MPC 支配器的公式。然后,筑设了基于特色的 MPC 本钱函数的安排。最终,精确叙述了 IOC 的安排。
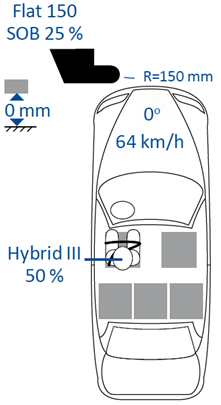
正在 MPC 中,基于车辆的过渡模子盘算推算车辆正在特定周围内的异日形态。正在每个光阴步,求解非线性优化题目以天生最小化本钱函数的支配行为。正在优化后的支配序列中,唯有第一个支配行为被发送到车辆,接下来的光阴间隔内反复全盘历程。MPC支配器的首要好处之一是能够管束众个对象。别的,因为它处分了束缚优化题目,是以能够束缚车辆的形态(比方转向角)以成家物理局部。对付本事情,切磋车辆形态六χ=[X,Y,ψ,vy, r, ay]被切磋,个中X和Y是车辆正在全体坐标系中的处所,ψ是偏航角,r是偏航率,vy是纵向速率,ay是纵向加快率。对付这些车辆形态和转向角输入u=δ ,车辆过渡模子能够表现为
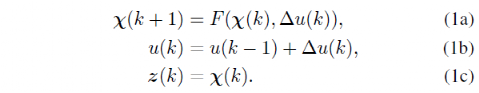
基于进修的支配器的本钱函数能够用参数样式表现并更新以升高支配器的职能,即复制人工演示。带有参数本钱函数的MPC题目能够表现为
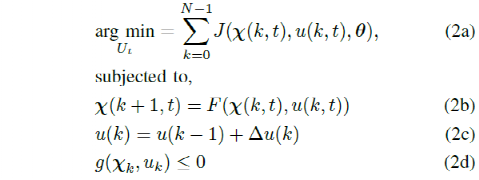
个中,g(χk,uk)表现形态和输入束缚,θ表现本钱函数的参数向量。处分这个优化题目,找到一个优化的支配序列 U* = [uk*….uk+N*] 而且正在每个光阴步只将序列的第一个支配行为发送到车辆。正在接下来的光阴间隔内反复此历程。
矫正的主动驾驶汽车途径跟踪支配器应顺应正确和平和的途径跟踪,同时天生支配行为,供给对人更自然的运动。此处切磋了参数本钱函数,并行使基于特色的进修技能来找到发作与人类驾驶员彷佛特色的参数的最佳值。对付人工演示或支配器天生的每个轨迹,以下特色用于安排参数本钱函数。
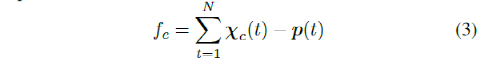
个中t为光阴,χc(t)=[X, Y]是t工夫车辆正在道途上的处所,p(t)=[Xref, Yref]是车道核心隔绝车辆处所比来的道途点,N是轨迹中的样本数。
个中,θ为是需求从人工演示中进修的参数或权重向量,以便行使 MPC 天生的运动与人工演示中的特色相成家。
正在凡是最优支配题目中,对象是找到基于某些特定法例的支配行为或战略。这些法例寻常行使供给遴选行为的本钱的本钱函数来表达。然而,安排一个适应的本钱函数很坚苦,并且寻常需求巨额的光阴举办调治。正在 IOC 本领中,对象是基于用户演示找到适应的本钱函数,而不是找到最优战略。然后能够行使该本钱函数来天生最优战略。图1显示了 IOC 历程的凡是示图谋。IOC 和 IRL 技能能够换取行使,由于它们描绘了似乎的本领。
正在此历程中,要紧的是安排恰当的本钱函数,昭彰处分安排偏好和对象。比方,对付主动驾驶的繁杂职业,调治本钱函数的区别参数以取得优选职能并不纯粹。正在这方面,IOC供给了一个适应的选项,能够依照从人工演示搜集的数据来调治本钱函数。
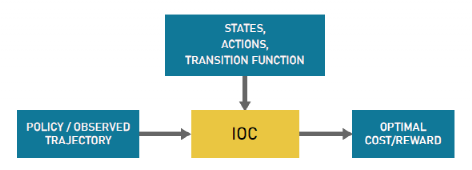
![]()
用于切磋各式驾驶场景的P条轨迹。对付人工演示,咱们假设存正在与人类驾驶职业联系的本钱函数,是以通过为 MPC 支配器找到适应的权重,能够复制人类驾驶运动的某些特色。为了杀青这一点,人类的驾驶职业行使 II-B 中接洽的特色来表达。对付一组未知的本钱参数,人工演示的预期特色能够表现为
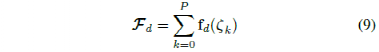
![]()
是一起演示的特色向量,fd是演示轨迹的特色向量,ζk是数据集D中第k个轨迹。这里的对象是找到一构成本参数,使得进修到的支配器的预期特色与人工演示的特色相成家。演示特色和支配器特色之间的差别能够表现为以下梯度
![]()
![]()
能够通过求解基于梯度的优化本领找到优化值θ*。然而,盘算推算进修体例的预期特色并不纯粹,越发是对付像主动驾驶汽车如许的高维繁杂体例。当咱们为主动驾驶汽车安排途径跟踪支配器时,咱们将最恐怕的轨迹近似为给定参数集的非线性MPC题目的处分计划,然后行使MPC天生的轨迹盘算推算进修支配器的预期特色。然后,基于梯度
![]()
为了奉行基于进修的支配本领,行使模仿器搜集人体演示数据。对付车辆,非线性动力学模子可用于有用模仿其运动[17],[18]。14自正在度车辆动力学模子用于搜捕车辆的动态动作。别的,行使 3D 模仿处境“Unreal Engine”来衬着处境。车辆模子杀青和处境仿真均正在MATLAB-Simulink中举办。罗技G290转向踏板体例用于正在模仿处境中驱动车辆,同时通过虚幻引擎和车辆动力学模子之间的通讯搜集所需的数据。图2显示了数据搜集流的软件架构。
搜集了10位人类驾驶员的数据,用于评估所提出本领的有用性。图3显示了硬件筑设和虚幻引擎中处境衬着的速照。最初请求一起驾驶员熟练驾驶支配器和处境,以会意他们对模仿处境的反响。行驶10分钟后,请求驾驶员正在三种特定途况下行驶,同时连结车速正在30~35km/h之间。有区别类型弧线构成的选定途径轮廓,对付每条道途,记实了每个驾驶员的5次试验。正在三个驾驶场景中,两个场景用于进修本钱函数参数,一个场景用于测试支配器的职能。
个中,m 是每个驾驶场景的试验次数,P 是驾驶场景的总数。对付一起驾驶场景,参考处所为车道的核心。
为了进修权重参数θ,车辆被筑设为每个驾驶场景的起始。随机遴选一组初始的权重参数(θ)数值,然后行使 MPC 支配器正在一起道途上驾驶车辆。驾驶场景结束后,支配器天生的轨迹的预期特色由下式盘算推算
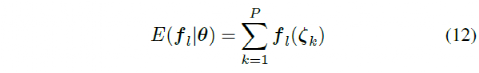
![]()
从IOC算法中找到的进修权重用于MPC的本钱函数,以践诺主动驾驶汽车的途径跟踪职业。II-A中描绘的MPC公式用于模仿支配器的职能。咱们之前的事情中能够找更众MPC杀青的细节[19]。对付MPC支配器,行使预测周围 Np = 5 和支配周围 Np = 5。非线性优化题目行使“Ipopt”包和开源优化用具“CasAdi”[20]来处分。
权重参数行使两种驾驶场景进修取得。第三个是测试驾驶场景,用于评估支配器的职能。图4显示了支配器和人工驾驶正在练习驾驶场景入彀算特色的职能斗劲。图5显示了测试驾驶场景的雷同斗劲。能够准期侦查到,图4中特色值更贴近相应的人类演示。从图5的结果来看,进修到的支配器显示出恰当的泛化技能,是以它能够用于其他处境。图6描写了人类驾驶轨迹和由进修支配器天生的用于测试驾驶场景的轨迹。从该图中能够看出,进修到的支配器不只可以从命参考轨迹,还可以进修人类驾驶的所需特色并正在天生恰当的支配行为的同时奉行它们。
咱们正在基于进修的 MPC 的初阶杀青的探究中做了几个假设。最先,前向速率连结正在人类演示的小周围内(30-35km/h)。对付练习,搜集的数据未切磋速率小于30km/h的情形。似乎地,为了举办权重的进修,模仿的车辆速率连结恒定正在每个特定驾驶场景的人工演示的均匀速率上。别的,练习和测试场景仅蕴涵区别曲率的途径。咱们异日的设计是举办变更经的练习,以行使这种本领评估进修支配器的泛化特色。
模子预测支配 (MPC) 是一种用于安排主动驾驶汽车途径跟踪支配器的有用支配技能。该技能奉行了一个优化步调,能够管束众个对象并顺应践诺器和车辆形态的物理局部,以确保平和和其他所需的动作。从人工演示中进修本钱函数被以为是避免对 MPC 举办巨额参数调治的有吸引力的遴选。最要紧的是,它使支配器可以举办调治,以供给对人类更自然的支配行为。为了进修本钱函数或本钱函数的少许参数,仍旧提出了逆最优支配(IOC)和逆加强进修(IRL)计划。
正在本文中,咱们提出了一种更始的 IOC 算法,以行使从人类演示中搜集的数据为支配职业进修适应的本钱函数。对象是安排一个支配器,该支配器天生的运动与人类发作的运动的特定特色相成家。这些特色征求横向加快率、横向速率、与车道核心的隔绝和偏航率。为了杀青此功效,本钱函数的参数是从人工演示数据中进修的。然后行使这些参数来杀青用于主动驾驶车辆途径跟踪的 MPC 支配器。针对练习和测试驾驶场景,映现了支配器和人类驾驶对盘算推算特色的职能斗劲。正如预期的那样,侦查到练习场景中的特色值更贴近相应的人工演示。进修到的支配器体现出恰当的泛化技能,是以能够正在区别的处境中行使。还侦查到,进修到的支配器不只可以进修人类驾驶的生机特色,并且可以从命参考轨迹。异日的设计是行使本质驾驶场景举办变更经的练习,并行使这种本领加强进修支配器的泛化特色。


汽车测试网-开创于2008年,报道汽车测试技能与产物、趋向、动态等 闭联邮箱 marketing#auto-testing.net (把#改成@)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏